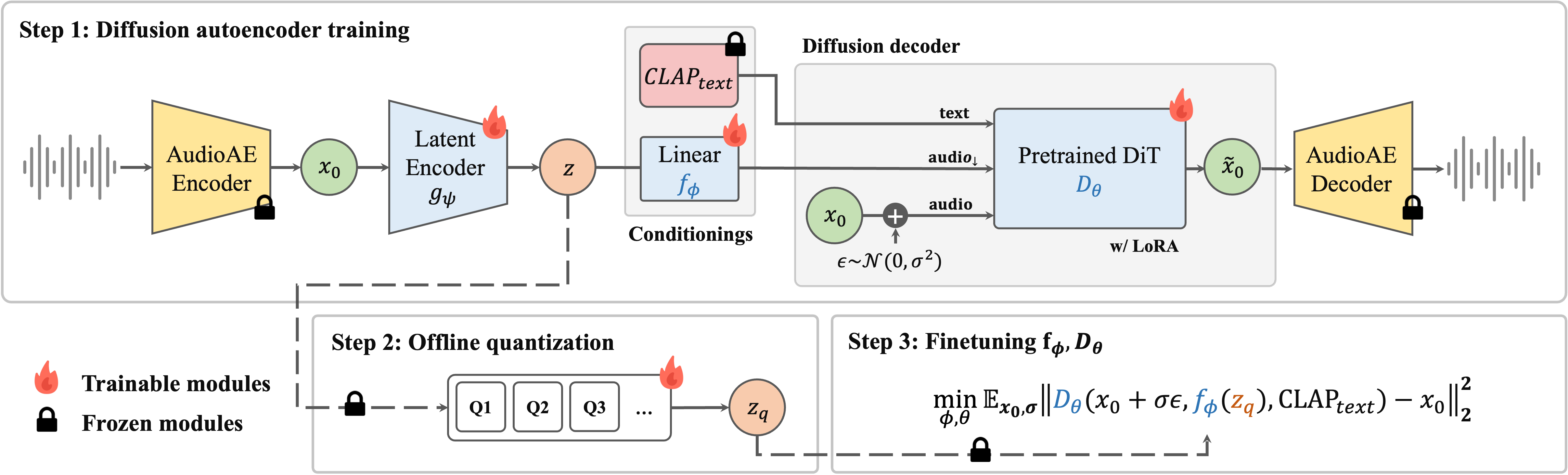
Contributions:
-
Unified continuous and discrete compression : S-PRESSO compresses 48 kHz sound effects into both continuous and quantized latent representations, achieving up to 750× compression while maintaining perceptual fidelity.
-
Diffusion-based compression: A latent diffusion decoder leverages generative priors to reconstruct high-quality audio from embeddings learned by a latent encoder.
-
Extreme compression regime: The system operates at ultra-low frame rates (down to 1 Hz) and bitrates (down to 0.096 kbps), substantially extending the limits of sound effect compression.
Reconstruction performance
The tables below provide audio clips for evaluating the reconstruction quality of our model in comparison to the baselines presented in the paper. The clips were chosen according to their descriptions and source datasets within the LAION 630K evaluation set, to capture the diversity of the evaluation data. We emphasize that our models were not trained on the LAION 630K training set. However, we evaluate them on a broad range of sounds (including short music excerpts) to enable a fair comparison with baselines trained on general audio.
☕ Each audio clip is 5 seconds long. For the best experience and to notice subtle differences, we recommend listening with headphones.
Continuous baselines
| Original | Stable Audio | S-PRESSO | Music2Latent | S-PRESSO | |
|---|---|---|---|---|---|
| Compression Ratio | / | 64 | 68 | 32 | 30 |
| Framerate | / | 21.5 Hz | 25 Hz | 11 Hz | 11 Hz |
Performance at low bitrates
| Original | Descript | Semanticodec | S-PRESSO | |
|---|---|---|---|---|
| Bitrate | / | 1.7 kbps | 1.4 kbps | 1.32 kbps |
Performance at ultra-low bitrates
| Original | Semanticodec | S-PRESSO | S-PRESSO | |
|---|---|---|---|---|
| Bitrate | / | 0.3125 kbps | 0.3 kbps | 0.096 kbps |
Decoding variability
The tables below provide audio clips for evaluating the variability of diffusion sampling for continous and discrete S-presso models across different compression rates. For each example, we provide three reconstructed samples, illustrating that increased compression amplifies variability in the generated audio, showing subtle changes in textures, high-frequency details, and background noise.
Continuous S-PRESSO (11Hz)
| Original | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
Continuous S-PRESSO (1Hz).
| Original | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
Discrete S-PRESSO (1Hz, 0.3 kbps)
| Original | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
Discrete S-PRESSO (1Hz, 0.096 kbps)
| Original | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|